
Founder of Chatwith
Retrieval Augmented Generation and Reranking in Custom ChatGPT
Chatbots have come a long way, thanks to advancements in Artificial Intelligence (AI). One of the frameworks making waves in this field is Retrieval Augmented Generation (RAG). In this article, we'll dive into how RAG, reranking, Large Language Models (LLMs), and query embeddings are working together to help create custom ChatGPT chatbots that are smart and grounded.
What's Retrieval Augmented Generation (RAG) All About?
Picture this: You're at a party, and someone asks you a question about quantum physics. You quickly pull out your phone, look up some information, and then smoothly incorporate it into your response. That's essentially what RAG does for AI!
Think of RAG as a super-smart librarian for your chatbot. It has two main parts:
- The Retriever: This part searches through a vast database to find relevant information based on the user's question.
- The Generator: Once the retriever finds the right info, the generator uses it to craft a response.
For example, if you ask a customer service chatbot, "What's your return policy for electronics?", the retriever would pull up the relevant policy information, and the generator would use that to create a clear, concise answer.
How Does RAG Make Chatbots Better?
RAG helps chatbots give answers that are both on-point and natural-sounding. It's like having a knowledgeable friend who always knows where to look for information and how to explain it well. This tech is super useful in fields like customer service, healthcare, and education.
Imagine a medical chatbot using RAG to provide accurate information about symptoms. It could retrieve data from trusted medical sources and generate an informative response, advising the user whether they should see a doctor.
Query Embeddings: Figuring out the Meaning
Query embeddings are like translators that turn text into a language that computers can understand better. They convert user questions into numerical representations, making it easier for the system to find relevant information quickly.
This technology is particularly useful for understanding the intent behind a question. For instance, the queries "Where can I buy a new laptop?" and "What's the best laptop for gaming?" might look similar to a basic system, but query embeddings help the system understand the different intents and provide more accurate responses.
Vector Database: The Library of All Information in RAG Systems
Vector databases play a crucial role in making RAG systems more efficient. Think of them as super-organized digital libraries that store data in a unique way. Instead of using traditional tables, vector databases represent data as numerical vectors ("embeddings").
How do vector databases work in practice within an information retrieval system? Let's say you're building a chatbot for a fashion retailer. When a customer uploads an image of a dress they like, the system converts that image into a vector. The vector database then quickly searches through thousands of product vectors to find similar items, based on semantic similarity, allowing the chatbot to recommend matching or complementary products.
In the context of RAG, vector databases enhance the retriever's ability to find relevant information quickly. This means when a user asks a question, the chatbot can more efficiently locate the most useful pieces of information to generate its response, leading to more accurate and helpful interactions.
Reranking: Giving RAG an Extra Boost
Reranking is like having a fact-checker for the retrieval system. Here's how it works: after the retriever pulls up relevant documents from the vector database, the reranker steps in to sort them by how well they match the original question. This ensures that the most useful information gets priority based on its relevance.
Let's look at a practical example. Imagine you're planning a beach vacation and ask a travel chatbot, "What are the best beaches for surfing?" The retriever might pull up information about various beaches, surfing techniques, and beach safety. The reranker then analyzes all this information and prioritizes it based on relevance. It might put articles about popular surfing spots, current wave conditions, and expert recommendations at the top of the list, while pushing general beach information or outdated surfing guides lower down.
This sorting process helps ensure that when the chatbot generates its response, it's using the most relevant information available. It's not just about finding similar information – it's about figuring out the most accurate information for your specific question.
Large Language Models (LLMs): The Brains Behind the Operation
LLMs are the powerhouses that help chatbots understand and generate human-like text. In RAG systems, they play a crucial role in making sense of user queries and crafting coherent responses.
These models can grasp context and nuance, allowing chatbots to handle complex questions. For example, an LLM-powered chatbot could understand the difference between "How do I reset my password?" and "Why can't I reset my password?", providing appropriate answers for each scenario.
Putting It All Together: Advanced RAG in Action
When you combine all these technologies in a system like Custom ChatGPT, you get a chatbot that's not just smart, but also informative and context-aware. Here's a quick example of how it might work:
User: "I'm planning a trip to Japan. What should I know about their etiquette?"
- The query embedding system understands this is about Japanese cultural norms.
- The retriever pulls information from various sources about Japanese etiquette.
- The reranker prioritizes the most relevant and up-to-date information.
- The LLM generates a response using this information.
- The chatbot replies with something like: "When visiting Japan, it's important to be mindful of their customs. Some key points: bow instead of shaking hands, remove your shoes before entering homes, and avoid tipping as it's not customary. Also, be quiet on public transportation and don't eat while walking on the street."
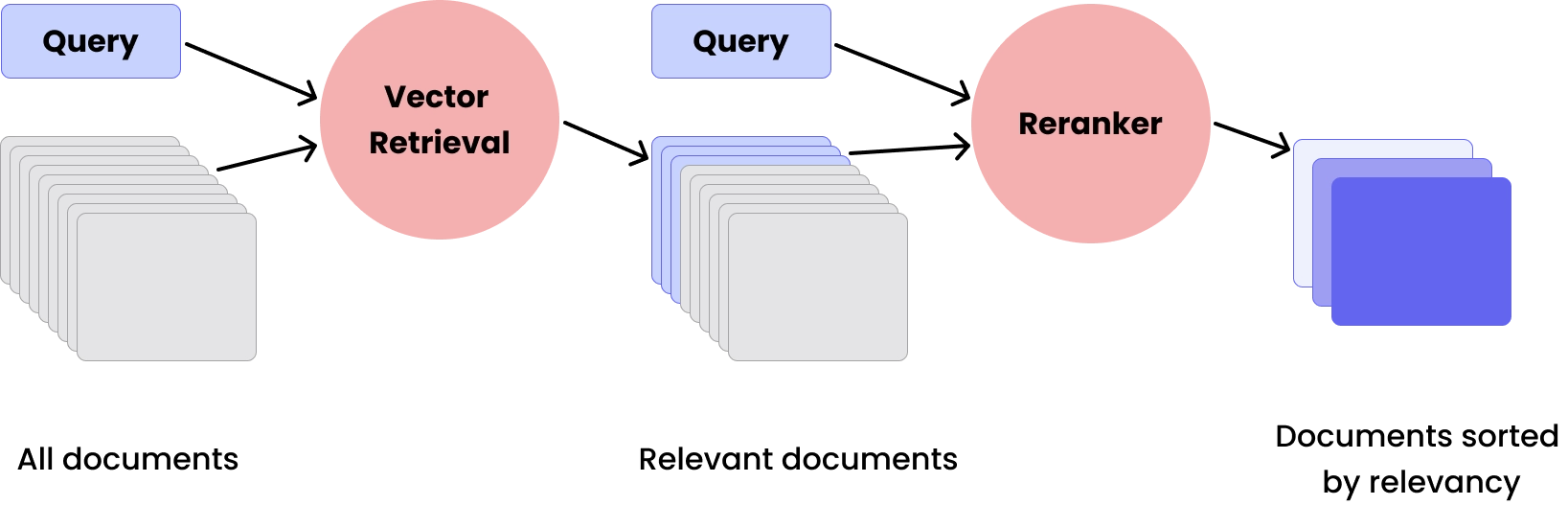
What RAG components are used at Chatwith?
At Chatwith, we utilize RAG and its related technologies in our chatbots to deliver responses that are more precise, contextually relevant, and useful. We selected providers offering the highest impact products:
1. LLM and Query Embeddings: OpenAI
OpenAI is a leading AI research company known for developing powerful language models and embedding technologies. Their GPT (Generative Pre-trained Transformer) models, such as GPT-4.1 and GPT-4o, are widely used for natural language processing tasks. For query embeddings, OpenAI offers the "text-embedding-3-small" model, which converts text into high-dimensional vectors that capture semantic meaning. These embeddings are crucial for semantic search and similarity comparisons in AI applications.
2. Vector Database: Pinecone
Pinecone is a company that provides a purpose-built vector database for machine learning applications. Their vector database is designed to store and efficiently search through large collections of high-dimensional vectors, making it ideal for AI-powered search and recommendation systems. Pinecone's database supports fast similarity search using algorithms like Approximate Nearest Neighbors (ANN), allowing developers to quickly find the most relevant data based on vector comparisons.
3. Reranking: Cohere Rerank 3
Cohere is an AI company that offers various natural language processing services, including their Rerank product. Cohere Rerank 3 is a specialized model designed to improve search results by reordering a list of candidates based on their relevance to a given query. This reranking step helps to refine search results, ensuring that the most pertinent information is presented first. Rerank 3 combined with OpenAI's query embeddings results in almost 20% improvement in response accuracy. We're happy to offer this powerful combo at Chatwith.
Conclusion
By leveraging RAG and its associated technologies, chatbots can provide more accurate, contextual, and helpful responses, making our interactions with AI more natural and productive. As these technologies continue to evolve, we can look forward to even smarter and more capable chatbots in the future.
More from our blog

Chatbot Versioning Explained for Developers in 2026
Discover what is chatbot versioning explained and how it ensures AI stability. Learn crucial versioning practices for reliable chatbot deployment!

How to improve e-commerce customer support with a custom ChatGPT chatbot
Customize ChatGPT for e-commerce to offer 24/7 support, personalized interactions, and reduce costs, while improving the online shopping experience.